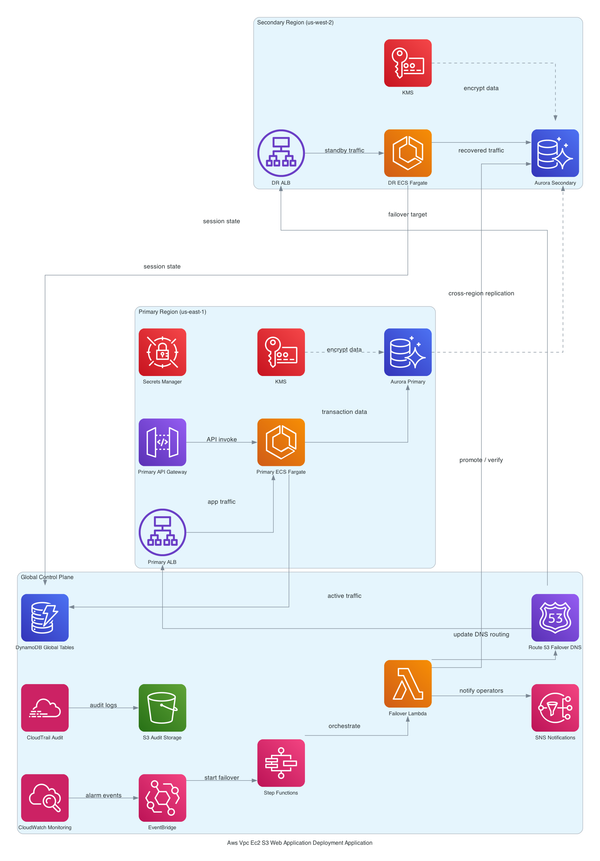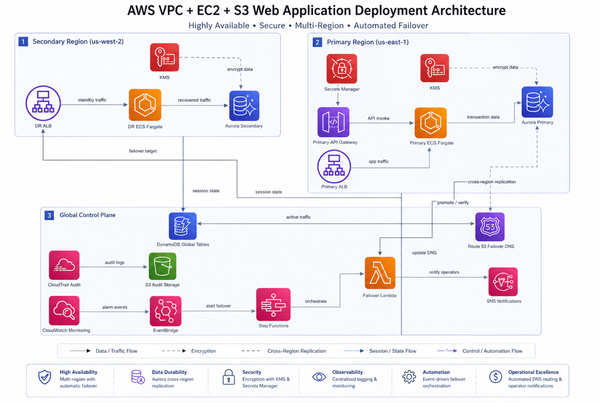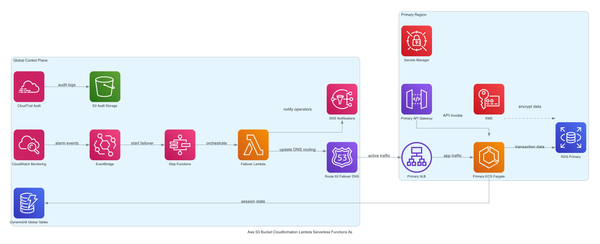
AWS CDK S3 to Lambda via EventBridge: Full Cost and Architecture Breakdown
Most S3-to-Lambda setups skip CloudTrail data events entirely and pay for it later with brittle fan-out and zero audit trail. This post walks through a CDK TypeScript stack that routes S3 events through EventBridge properly — VPC placement, KMS encryption, Secrets Manager, cost model, and the failur