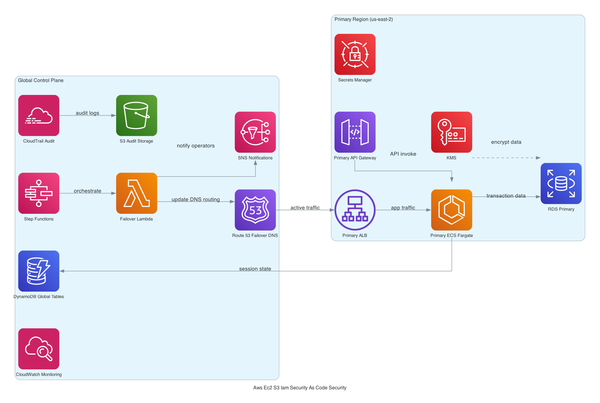
Someone on your team hardened your AWS account six months ago. They clicked through IAM, tightened some security groups, enabled CloudTrail in three regions (not all of them), and added a few Config rules that looked right. Then they left. Now your security audit is back and you have 23 findings, a CloudTrail gap in ap-southeast-1, and nobody can tell the auditor what was configured or why. This is the problem that aws cdk security as code actually solves - not the initial hardening, but the fact that security configuration has the same drift problem as application config, and most teams treat it like a one-time task.
This post walks through a CDK TypeScript stack that encodes VPC isolation, KMS key policies, IAM least-privilege, AWS Config rules, WAF, and CloudTrail into version-controlled, PR-reviewable infrastructure. Every control is a construct. Every change is a diff. Audits stop being a fire drill.
Who Is This Pattern For
OK so you need this if you're an infrastructure or platform engineer who owns the compliance posture for one or more AWS accounts and has felt the specific pain of being asked "can you reproduce this configuration?" and not having a great answer.
More specifically: if your team has more than two engineers touching AWS, if you're approaching any kind of compliance review (SOC 2, ISO 27001, internal security audit), or if you've ever said the phrase "I think that Config rule was there before I joined" - this pattern is for you. It assumes you already know CDK. You don't need to be a security specialist, but you should be comfortable reasoning about IAM policies and VPC topology without reaching for the console.
Problem the Pattern Solves
The real problem isn't that your AWS account is insecure. It's that your security posture is undocumented tribal knowledge, not code.
Manual console changes don't leave a diff. CloudTrail tells you that someone changed a security group - it doesn't tell you why or whether that change was intentional hardening or an accident. Config rules that were added but never enforced might as well not exist. IAM policies that grew by copy-paste until "least-privilege" became aspirational rather than actual. You know how your UPI payment shows "success" but the merchant says "not received"? Security configurations are actually like that - the console shows everything looks fine, but the actual posture drifted three months ago and nobody noticed.
Writing your WAF rules, KMS key policies, Config rules, and VPC topology in CDK doesn't automatically make your account more secure on day one. What it does is make every future change a pull request with a diff. Your compliance posture becomes auditable by design rather than by retrospective screenshot. That's the shift. Right?
Context and Scale Assumptions
This pattern works well in a specific range. Single AWS account, maybe two (prod and staging). Somewhere between 5 and 50 EC2 instances. A team that's serious about compliance but doesn't yet have a dedicated security engineering function. You're probably not in AWS Organizations with 40 accounts and a Security Hub aggregator yet - if you are, the paid section covers what breaks at that scale.
A few things I'm assuming: your workloads are in one region (multi-region changes the CloudTrail setup), you have some kind of CI/CD pipeline where CDK synth and deploy run (GitHub Actions, CodePipeline, whatever), and you're OK with VPC endpoints instead of NAT Gateways. That last assumption is load-bearing - I'll explain why in a minute.
System Boundaries and Request Flow
Here's the overall shape. A multi-AZ VPC with three subnet tiers: public (for load balancers only), private (for EC2 workloads), and isolated (for RDS, ElastiCache - no route to the internet at all). All EC2 instances sit in private subnets. They never touch the public tier.
The SecurityConfig class is the spine of the whole thing. It's a single TypeScript class that holds your CIDR ranges, allowed prefix lists, trusted account IDs for KMS, and anything else that touches multiple constructs. The VPC construct reads from it. The security group construct reads from it. The KMS key policies read from it. This is intentional - you want one place to make security decisions, not twelve. Right?
Customer-managed KMS keys encrypt S3, Secrets Manager, and CloudTrail. CloudTrail writes to a locked-down S3 bucket (bucket policy denies everything except the CloudTrail service principal) and ships to CloudWatch Logs for near-real-time alerting. AWS Config records resource-level changes continuously and enforces managed rules - things like s3-bucket-public-read-prohibited, restricted-ssh, iam-password-policy. WAF sits in front of any public-facing ALB. Secrets Manager vends credentials instead of environment variables.
For the VPC subnet isolation construct specifically, here's a sanitised version of what the CDK looks like:
const vpc = new ec2.Vpc(this, 'AppVpc', {
cidr: securityConfig.vpcCidr,
maxAzs: 3,
subnetConfiguration: [
{
name: 'Public',
subnetType: ec2.SubnetType.PUBLIC,
cidrMask: 24,
},
{
name: 'Private',
subnetType: ec2.SubnetType.PRIVATE_WITH_EGRESS,
cidrMask: 24,
},
{
name: 'Isolated',
subnetType: ec2.SubnetType.PRIVATE_ISOLATED,
cidrMask: 24,
},
],
natGateways: 0, // VPC endpoints instead
});
natGateways: 0 is doing a lot of work there. More on that in a second.
For AWS CDK networking patterns that go deeper on the VPC layer, I've covered the subnet topology decisions in more detail here.
Why This Shape Over Alternatives
The SecurityConfig centralisation is the most controversial decision here. Every subnet, every security group, every KMS key policy reads from the same config object. That's a high-blast-radius single point of change - a wrong CIDR there propagates everywhere simultaneously. Why do it anyway?
Because the alternative is actually worse. When security config is scattered across 12 constructs, you get 12 places where someone can introduce a drift. The blast radius of a correct centralised change is the same as the blast radius of a wrong one. At least centralised, it's one PR to review. This is actually pretty clever once you sit with it.
On NAT Gateways vs VPC endpoints: I went with zero NAT Gateways and VPC endpoints for every AWS service the EC2 instances call. Why? NAT Gateways cost $0.045/hour per AZ plus data processing fees. For three AZs, that's roughly $100/month before any traffic. VPC endpoints cost $0.01/hour per AZ for interface endpoints - still adds up, but the unit economics favour endpoints once your workloads are calling AWS APIs heavily. More importantly, NAT Gateways give you egress to the internet, which is threat surface you don't want for backend EC2 instances. VPC endpoints keep traffic inside the AWS network entirely.
The risk is what the trade-off list says: missed endpoints cause silent connectivity failures. Your Lambda rotation function for Secrets Manager, your CloudWatch Logs agent, your SSM agent - they all need explicit endpoints. And here's the kicker - the first time I deployed this pattern I missed the com.amazonaws.region.secretsmanager endpoint and spent two hours debugging why Secrets Manager rotation was failing silently. (I learned this the hard way on a Friday deploy.)
Not ideal.
On AWS Config vs Security Hub: Security Hub aggregates findings from GuardDuty, Inspector, Macie, and Config into one place and makes cross-account rollup much cleaner. But it adds cost (roughly $0.001 per security check per resource per region) and operational complexity that doesn't pay off for a single account. Config managed rules are cheaper and more transparent for this scale. The full comparison is in the paid tier.
For IAM least-privilege implementation details in CDK, this pattern from InfraTales covers the role and policy construct design.
What Breaks When Things Go Wrong
So basically, failure modes. Let me be direct about the ones that have actually surprised me.
KMS key deletion. This is the scary one. KMS key deletion has a mandatory 7-30 day waiting period, which sounds safe. It's not, because if someone schedules a CMK for deletion and CloudTrail's S3 bucket depends on it, you start getting decrypt failures before you get a clear warning. The decrypt errors surface as CloudTrail delivery failures, not as "hey your key is being deleted." I did not see this coming the first time. By the time you connect those dots, recovery requires figuring out which exact key was used across which exact resources. Avoid this by adding a DeletionProtection construct and an explicit resource tag on all CMKs.
Config SNS notifications with no dead-letter. Config rule non-compliance goes to SNS. If your SNS topic subscription is misconfigured - wrong email, Lambda subscriber with an IAM issue, whatever - compliance drift accumulates completely silently. You find out at the next audit, not when the drift happens. Classic AWS. At minimum: test your SNS delivery path separately after deploy.
Secrets Manager rotation in a private subnet. Rotation Lambdas run inside the VPC. They need a VPC endpoint or NAT to call the Secrets Manager API. Missing this endpoint means rotation fails silently - the credential just doesn't rotate. Your application keeps running on the old secret until it expires, then everything falls over at once, at 3 AM, when you have no idea why. (Don't ask how long this took me to figure out the first time.)
WAF rule ordering. Rule priorities are fixed at deploy time. A bad priority order that lets a known-bad pattern through before a block rule fires won't surface during cdk synth or cdk deploy. It only surfaces in traffic analysis after the fact. There's no static analysis for WAF rule logic in CDK - you're testing this in staging, not in CI.
How to Actually Operate This Thing
CloudWatch Log Insights queries on the CloudTrail log group are your first-line investigation tool. CloudTrail writes structured JSON to CloudWatch Logs, which means you can query for specific API calls, specific IAM principals, or specific resource ARNs without pulling raw S3 logs.
The CloudTrail S3 bucket is locked down to the CloudTrail service principal only - as it should be. But that means any ad-hoc investigation that needs raw log files requires assuming a specific role with S3 read access to that bucket. Make sure that role exists and is documented before an incident, not during one. Seriously. Set up Athena over the S3 bucket if you want fast queries. The paid section has a pre-built Athena query setup.
Oh, and another thing - Config dashboards in the console are actually pretty useful for compliance posture over time. But Config continuous recording generates a lot of noise in a busy account. Tune your recording scope to exclude high-churn resources (EphemeralBlockDevice, etc.) or your Config costs will surprise you.
For the full picture on AWS security and reliability architecture patterns, including cross-account designs, that's in the linked post.
Cost Drivers
The three things that add up faster than you expect:
Config continuous recording is ~$0.003 per configuration item. Sounds trivial. In an account with 200 EC2 instances and frequent deployments, that's potentially $50-100/month. Scope your recording to the resource types you actually have Config rules for.
KMS customer-managed keys are ~$1/key/month plus $0.03 per 10,000 API calls. At low volume, completely negligible. When CloudTrail, Config, and S3 are all generating high API call rates, the request charges compound. S3 SSE-KMS generates a KMS Decrypt call for every GET. Watch that line item - this blew my mind the first time I saw it on a bill.
WAF costs $5/month per Web ACL plus $1 per rule group and $0.60 per million requests. Attaching WAF to every ALB in a multi-environment setup adds $30-60/month per environment. If you have a dev, staging, and prod environment, that's $90-180/month just for WAF before any traffic. Decide early whether dev needs WAF or whether you're OK with the coverage gap.
For the detailed cost optimization breakdown for AWS compliance tools, including the Config cost model with per-account estimation, that's gated in the paid tier.
When Not to Use This Pattern
Skip this pattern if you're a solo founder in early stage. One KMS key, one Config rule, one WAF ACL - the overhead of maintaining this CDK stack will slow you down more than the compliance risk hurts you. Come back when you have a team.
Skip it if you're already in AWS Organizations with 20+ accounts and a Security Hub aggregator. This pattern is designed for single-account or dual-account setups. At that scale you need a different shape - a central security account, Config aggregators, SCP-enforced guardrails. This stack will actually fight you.
Skip it if your workloads genuinely need internet egress from EC2 instances. NAT Gateways aren't evil - they're just not in this pattern. You can add them back, but then you're maintaining a hybrid of endpoint-routed and NAT-routed traffic and the debugging surface gets messy.
Failure Edges
Three places this pattern breaks that aren't obvious.
Config drift after manual console changes. Someone opens a security group during an incident, forgets to close it. CDK doesn't detect this unless you run cdk diff in your pipeline. Without AWS Config rules watching for drift, your CDK-managed state and your actual AWS state slowly diverge. I've seen this happen at every single client.
KMS key deletion cascade. If someone schedules a CMK for deletion and a dependent resource still references it, decryption failures are silent at write time. You only find out when someone tries to read the data. The 7-day minimum wait period exists for a reason - use it to audit dependencies before confirming.
WAF rule ordering. AWS WAF evaluates rules by priority number. If your rate-limiting rule has higher priority than your SQL injection rule, a DDoS attack can bypass injection protection by exceeding the rate limit first. Rule ordering is not intuitive and most teams get it wrong on the first attempt. [editorial]
Observability and Operations
CloudTrail is your audit backbone - make sure management events are captured in every region, not just your primary. Data events on sensitive S3 buckets only (not all buckets - that gets expensive fast at high throughput).
CloudWatch alarms on three things minimum: WAF block rate spike, IAM access denied spike, and KMS decryption failure count. If any of these go above baseline, something is either misconfigured or someone is probing your perimeter.
VPC Flow Logs to CloudWatch Logs with a 14-day retention. Long enough for incident investigation, short enough to not blow your storage budget. If you need longer retention for compliance, ship to S3 with lifecycle policies.
When Not to Use It
This pattern is overkill for internal tools with no PII, no compliance requirement, and a single-digit user base. A single AWS-managed KMS key and a permissive IAM role won't fail any audit you'll face in that context.
It's also wrong for teams that don't have someone willing to own the security stack long-term. CDK-managed security controls need regular review - at minimum quarterly. If nobody is going to run cdk diff and review the output, you're better off with AWS Organizations SCPs managed at the org level.
Next Step
This pattern makes sense if you have a team, a compliance requirement, and the patience to maintain a VPC endpoint list. It's worth the operational overhead because every security change becomes a pull request - and that's what makes this approach actually defensible to an auditor.
free: The architecture overview above, the VPC subnet construct snippet, the SecurityConfig design rationale, and the top 3 cost drivers are all here.
paid: The full CDK construct walkthrough across all stacks (VPC, IAM roles, KMS key policies, CloudTrail bucket policy, Config rules, WAF), the complete VPC endpoint list for fully private EC2 workloads, the Config cost model with per-account estimation, what breaks when you scale into AWS Organizations, and the Secrets Manager vs SSM Parameter Store comparison - all in the InfraTales architecture patterns library.
If you're looking at this and thinking "I don't want to build this from scratch, I want someone to review what we already have" - that's a consulting path, not a tutorial path. You know where to find me.